Recently my team has been integrating Kubernetes with Hubot.
The objective being, Lets provide net new customers a way to write one line and create an entire project from scratch. Keeping in mind everything in our project is in containers. You might be asking, Why? Kubectl is great. This project was primarily to introduce Developers to Kubernetes without requiring a ton of knowledge around containers. We wanted to get them playing with it, launching new projects with containers with less complexity.
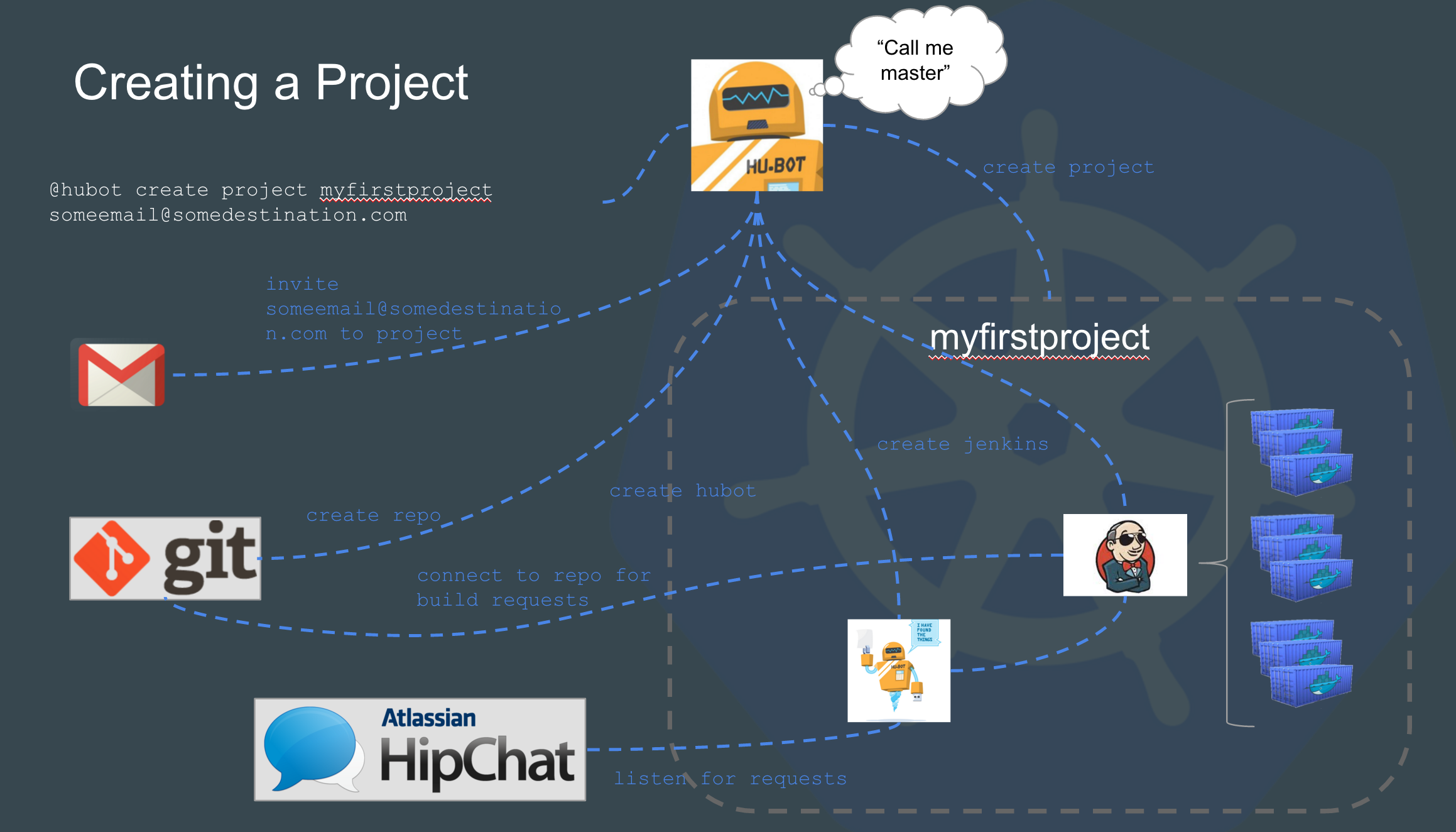
Real quick: Let me explain what is happening in the slide above. A Technical Project Manager or Program manager wants to create a new project. They run hubot create myfirstproject email@someemail.com this calls master hubot which then creates:
Git repository
Prepopulated data into the git repo
Separate namespace Kubernetes
A hubot to manage their own project/namespace
Jenkins build server which connects back to the new repo
Kubernetes service account
A new hipchat channel
Email invite to repository and chat channel
Repos and Hipchat are external to Kubernetes used via API calls. Having such a large organization (100s of development teams) we needed to deploy a generic Jenkins per project. So every project/development team gets their own Jenkins server. All jobs and specialized Jenkins configuration resides in the repository, not initially in Jenkins. All Jenkins jobs can be queried through Chat and run through Chat. Jenkins can be updated in a global fashion for features required across the organization.
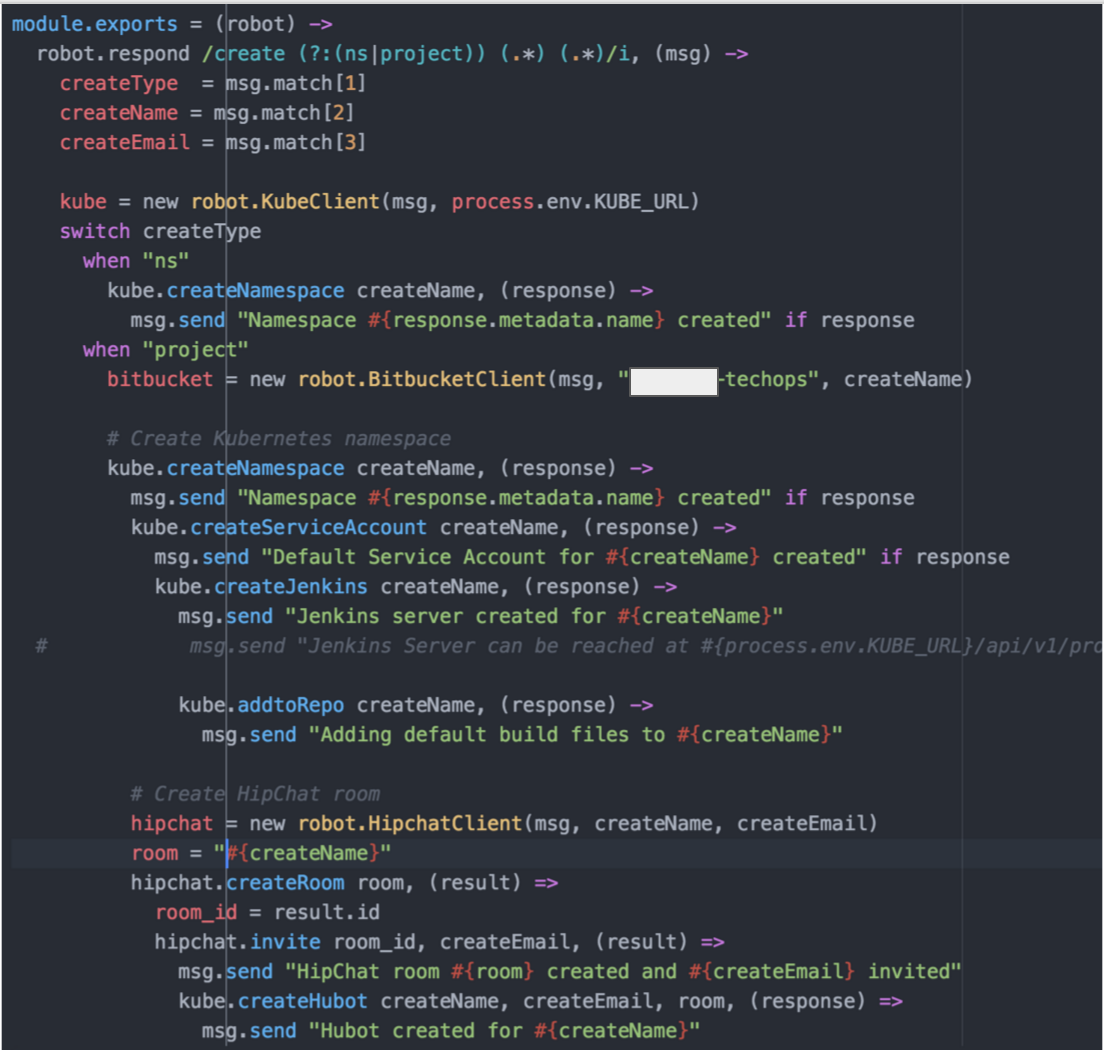
We have divided our Hubot scripts based on function.
kubecommands.coffee – Contains any master level Hubot functionality we don’t allow across all Hubots such as creating a new project.
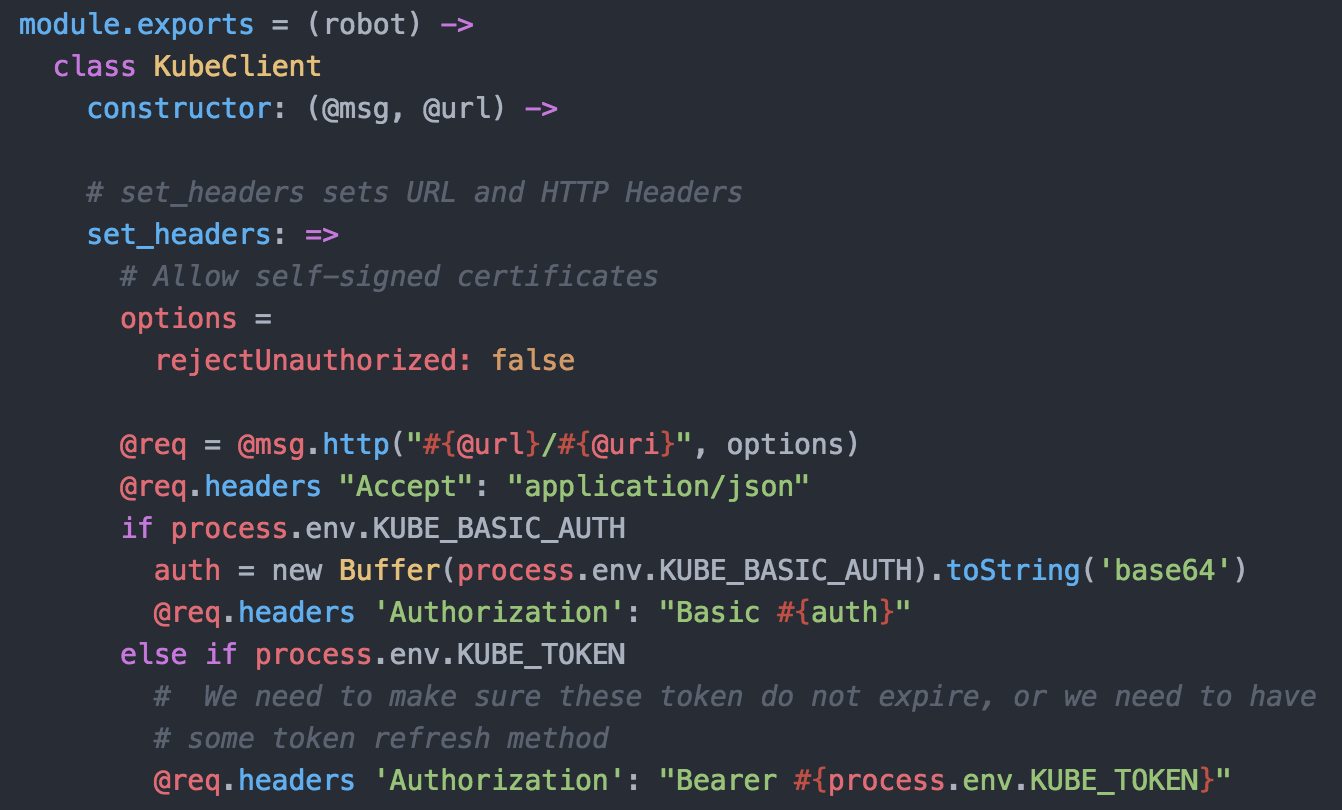
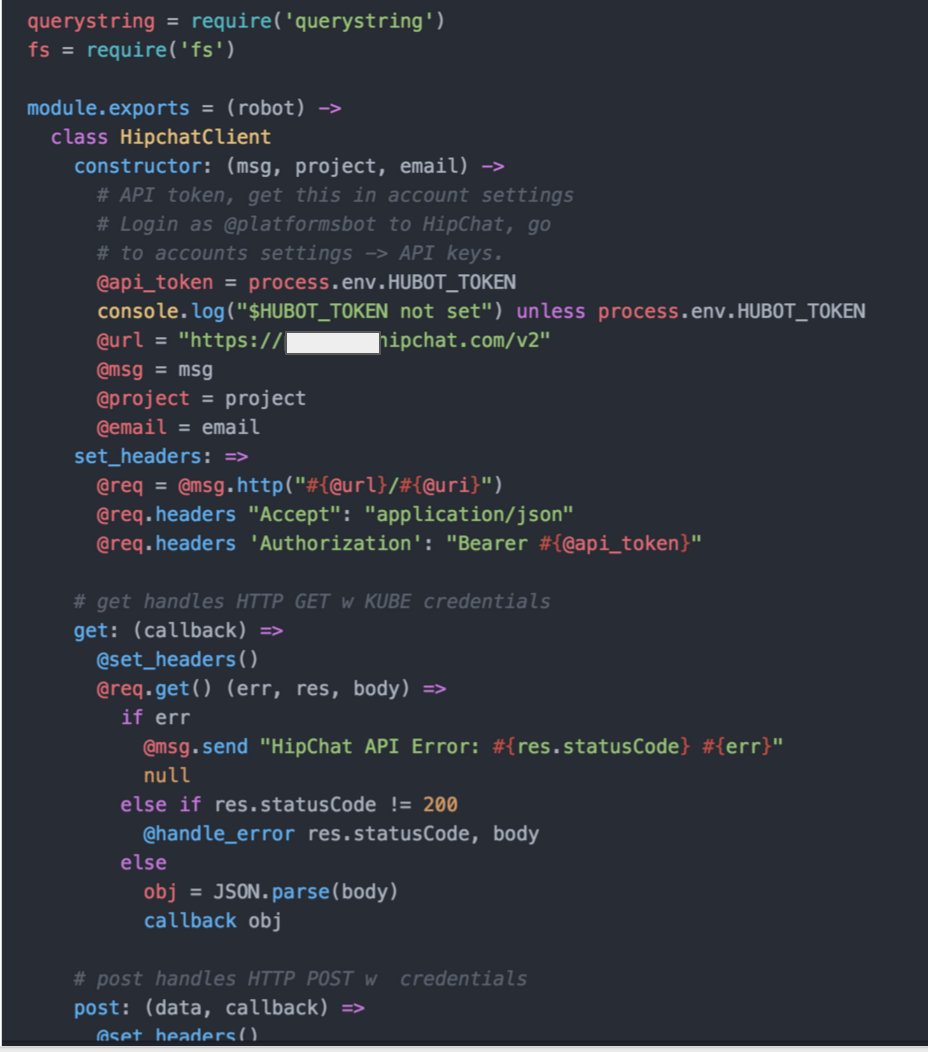
kubeclient.coffee – For communications directly with Kubernetes API. You will notice we are allowing for basic auth. This is changed already as we tokenize everything with OpenID Connect now.
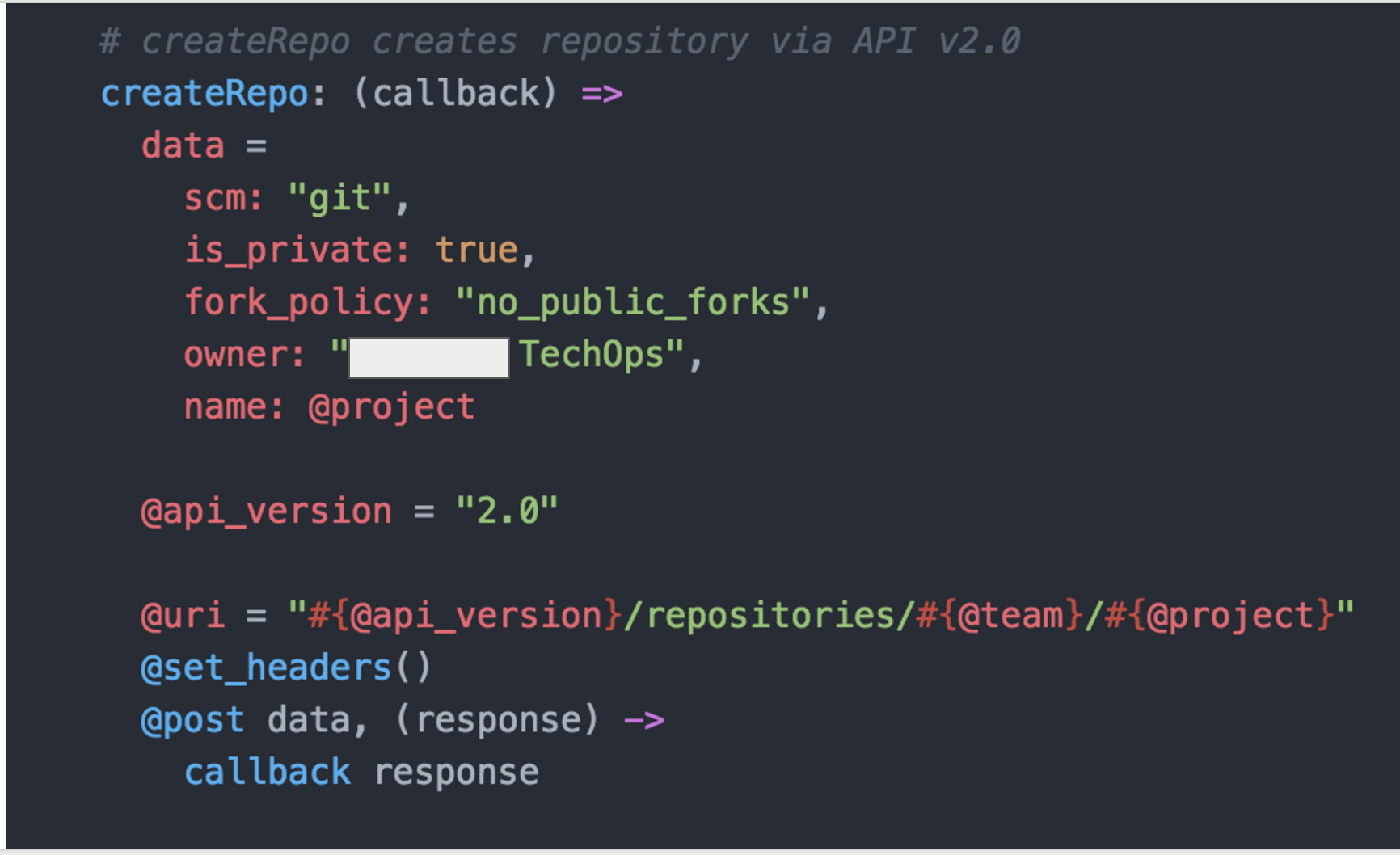
repoclient.coffee – For requests to our repo APIs
chatclient.coffee – For requests to our Chat client, in this case Hipchat
kubeproject.coffee – Hubot commands specific to hubots deployed into projects (limited set of functionality from the Master)
MySQL 5.6.21
Galera 25.3.5
Percona-xtrabackup-21 2.1.9-746-1.precise
Got error: 1047
Fix:
Database is probably in ‘initialized’ state. need to restart the service and check configuration.
WSREP_SST: [ERROR] Error while getting data from donor node: exit codes: 1 0 (20150325 09:17:28.755)
WSREP_SST: [ERROR] Cleanup after exit with status:32 (20150325 09:17:28.756)
WSREP_SST: [INFO] Removing the sst_in_progress file (20150325 09:17:28.759)
2015-03-25 09:17:28 6459 [ERROR] WSREP: Process completed with error: wsrep_sst_xtrabackup --role 'joiner' --address 'ip_address' --auth 'user:password' --datadir '/var/lib/mysql/' --defaults-file '/etc/mysql/my.cnf' --defaults-group-suffix '' --parent '6459' --binlog 'binlog' : 32 (Broken pipe)
2015-03-25 09:17:28 6459 [ERROR] WSREP: Failed to read uuid:seqno from joiner script.
2015-03-25 09:17:28 6459 [ERROR] WSREP: SST failed: 32 (Broken pipe)
2015-03-25 09:17:28 6459 [ERROR] Aborting
2015-03-25 09:17:28 6459 [Warning] WSREP:State transfer failed: -2 (No such file or directory)
2015-03-25 09:17:28 6459 [ERROR] WSREP: gcs/src/gcs_group.c:gcs_group_handle_join_msg():723: Will never receive state. Need to abort.
Fix:
Check innodb_data_file_path=ibdata1:256M:autoextend does not exist in my.cnf
Check that xtrabackup isn’t still running orphaned on either node “ps aux | grep mysql” on donor
Check apt-get install persona-xtrabackup-21 is installed (All servers should be running the same version)
Check ssh keys are correct and servers can ssh freely between each other
Make sure sst_in_progress file does not exist on the joining server
Check that the node joining has an /etc/hosts file entry for the donor (or DNS is good)
Check the wsrep_sst_method on the donor at runtime is xtrabackup-v2
Make sure the root:password in /etc/mysql/my.cnf is the same as what the localhost is or xtrabackup can’t use it and will bomb
Fix:
ibdata and log files are probably not the same size as the ones on the donor server. If innodb_data_file_path is set, this could be causing the problem.
Other interesting facts:
Syncing with xtrabackup:
– creating or dropping a database during sync will cause the node syncing to the cluster to drop
As Docker continues to grow in popularity there are quite a few things that become readily apparent. Fortunately I’m only going to address one of them. Enter envconsul to retrieve application config data at run time.
This post assumes you already have a running Consul server with some data you wish to retrieve.
envconsul was written by Hashicorp, a great company that I personally respect. In everything I’ve touched made by this great little company, I’ve yet to be disappointed. Their applications are rock solid.
Github Link:
https://github.com/hashicorp/envconsul
envconsul utilizes a key/value stored called Consul to retrieve configuration data and present them as environment variables to the application at runtime. This concept offers up a lot of opportunity around dynamic configuration, centralized configuration management and security because there aren’t free text usernames and passwords hanging around the file system. Not that any respectable company would ever do that right? No way. Never. Ok maybe it kinda happens almost always. With envconsul, we can solve that.
Build envconsul:
Currently there is no package in the general package managers for envconsul so I like to pull the repo, make the binary and copy it into /usr/bin which places the binary in the path and makes it immediately executable.
git clone https://github.com/hashicorp/envconsul.git
cd envconsul
make
If you decide you like envconsul, bake it right into your vm or container and you’ll always have it available.
Create a envconsul.cnf file:
Basically this file tells envconsul where the consul server exists.
consul = "consul.mydomain.com:8500"
timeout = "5s"
Add it to your Dockerfile:
I mentioned this had to do with Docker right? Well in the Dockerfile when you build your images you can bake envconsul right into to run command with something like the following:
Let’s imagine I have an Tomcat container with Apache Web Server running in front of it. In the command above I’m starting apache and then executing envconsul to call the consul server.
So what have I really done here?
I’ve set sanitize to false otherwise envconsul will replace “invalid” characters as underscores
I’ve referenced the envconsul.cnf with -config
I’ve set upcase to false cause being a Linux nut, I know some devs like to ingest environment variables that aren’t just uppercase
I’ve specified the key myblog to get data back from consul
I’ve added env so envconsul presents the results from consul as environment variables to catalina.sh
One thing I love about envconsul is when it provides the environment variables to the application, it is ONLY to the application. Logging in as root and running printenv won’t even provide the variables envconsul presents to the application.
This has been a very basic “get it up and running” scenario around envconsul. There are other things to explore like ssl, authentication and consul API Tokens so head over to the Github page dig in.
And if you have found this valuable, Tweet it please.
Being interested in geographically distributed database I’m providing some links to a cool MySQL plugin I use called Galera. Some may know this as Percona xtradb which is a whitelabel for galera developed by codership.
I’ve come to realize DevOps is highly misunderstood when its actually simple.
Tools + Communication + Automation = Speed, Stability and Value
Simple right?
So that’s how I look at it but what is the actual definition?
DevOps (a portmanteau of “development” and “operations”) is a software development method that stresses communication, collaboration, integration, automation, and measurement of cooperation between software developers and other information-technology (IT) professionals.
In theory its dead simple. In practice, it requires work just like everything else.
In my experience, even the companies that have a “culture of change” don’t change quite as easily as they may like to think. All the hemming and hawwing still happens. The nay sayers still exist. All the long drawn out meetings trying to convince key stakeholders still happen. And nothing moves quite as fast as the champion’s want them to AND THAT IS OK. Yep, you heard me right. Its perfectly ok.
Why do I say it’s ok? Because implementing a DevOps movement is scary and the vast majority of companies get it wrong while claiming a huge success. What generally happens is, we pick out the parts that sound cool like “Automation” (I’m 100% guilty of this), call our team members “DevOps Engineers” (managed not to do this), create a few meetings between Developers and Operations and call it good. Things get better between the teams, releases get better and we can deploy shit with the click of a button if we have spent enough time on it. But wait there’s more….if your company really gets a hair up their ass, they bake QA into the automation process. Thus hopefully we’ve gotten some integration between subsystems and system tests. Realizing that system tests generally catch issues which drive system integrations to happen. Bassackwards much?
After that, we officially have the gold nugget to success and true nirvana has hit its peak. We are deploying to production 80 times per day, PagerDuty never wakes us up and everything is air tight. right?
THE HOLY GRAIL!!!!
But as we soon come to find out, its not all beer and whiskey from here on out. The hard part is yet to come.
What’s missing? The most difficult parts are missing. feedback – collaboration – measurement of cooperation – communication. Which mostly boils down to Communication. But we can get away with what we have. I mean, its just a flesh wound right?
https://www.youtube.com/watch?v=ikssfUhAlgg
So inherently there is an order. A continuum by which DevOps is implemented. Easiest first, most difficult last. Go figure right? What’s the easiest? The parts that don’t require communication of course, automation and tools. Every geek can get behind those two. I mean, who doesn’t like tools? And who doesn’t like to click a button and see lots of cool shit happen that you can show off at your favorite meetup?
What do these other four things really buy us? How about planning, buy-in, innovation, reduced MTTR (mean time to recover), coordinated work, motivation, effectiveness, morale, speed, change lead time, retention, reduced costs from production defects, lower defect escape rate, reduced deployment times, and the list goes on.
I would propose that communication is the linchpin to a truly successful DevOps paradigm yet the one most avoided when getting started. Without it, all we really have is some cool automation.
But how do we do all this? Its hard right? It requires effort that geeks don’t generally engage in. How do we accomplish this part of DevOps and do it well? What makes this so difficult? Is it different for every company? Are we really that bad at communication? Or do we simply talk in different languages? Are their best practices to follow? How do we measure cooperation? What degree of collaboration is good?
In a follow-on post we’ll start to explore this paradigm of communication and how different companies make it happen.
Thoughts on communication:
Speak the same language – As odd as this sounds, encourage people to define what they mean by xyz. Make it a point to get definitions that may not be clear. I’ve seen and contributed to so many long conversations that could have been done in 3 minutes because multiple people were working from different definitions of the same word.
Innovate on communication – Have a retro on communication. Find out how to communicate in a manner that others can consume. Iterate on it.
Don’t allow different communication mechanisms to become a barrier – Allow people to consume Asynchronous information in different ways. Provide an ESB for communication if you will. Think ChatOps. Write some coffee script that will allow engineers to register with various types of communication. RSS feeds, email, message boards, online reporting, IM, Reddit, text to speech (maybe thats too far?). Let people consume information how they want to when its Asynchronous. Let them subscribe to what they think it important.
Provide venues for communication to happen organically – That sounds like a high level, completely ambiguous piece of no information. What I mean is, if multiple teams likes beer, make it a habit to go to lunch and drink every Friday. Find commonalities between the teams and exploit those to the companies benefit. Increase morale, collaboration and communication in one fail swoop. Some of the best ideas come from this one thing. DO NOT see this as a bunch of engineers taking off for the afternoon. You would be amazed at how many ideas come out of these venues.
Synchronous communication – should all happen the same way. Keep it consistent. One, maybe two technologies is fine. Beyond that is too much. Don’t have 10 different ways to constantly interrupt your colleagues.
Close the damn loop – All too often someone important gets left out of the communication loop. This can often happen because the email that got sent looks like the 1000 other emails received that day. Find a way to emphasize information that is important. You can even require an acknowledgement.
Painful to watch:
Hiring people that do both – really? I guess in a small organization it can work for some duration of time but I would have to argue that one person will never measure up to an engineer that is dedicated to one or the other. Its preposterous. If the application has any degree of complexity, the concept of one engineer being great at everything is plain ridiculous. What you end up with is a mediocre solution that is lacking in more than one thing. Its why we have QA, and developers and operations and performance engineers and security professionals. Because there is too much for one person to be good at all of it. Don’t be stupid, let people do what they are good at.
What do you think? What can we do to communicate better?