First off, mad props go out to Ben Somogyi and Martin Devlin. They have been digging deep on this and have made great progress. I wanted to make sure I call them out and all the honors go to them. I just have the honor of telling you about it.
You might be thinking right about now, “why an automated test framework? Doesn’t Kubernetes team test their own stuff already?” Of course they do but we have a fair number of apps/integrations to make sure out platform components all work together with Kubernetes. Take for example, when we upgrade Kubernetes, deploy a new stackstorm integration or add some authentication capability. All of these things need to be tested to ensure our platform works every time.
At what point did we decide we needed an automated test framework? Right about the time we realized we were committing so much back to our project that we couldn’t keep up with the testing. Prior to this time, we tested each PR requiring 2 +1s (minus the author) to allow a PR to get merged. What we found was we were spending so much time testing (thoroughly?) that we were loosing valuable development time. We are a pretty small dev shop. Literally 5 (+3 Ops) guys developing new features into our PaaS. So naturally there is a balancing act here. Do we spend more time writing test cases or actually testing ourselves? There comes a tipping when it makes more sense to write test cases and automate it and use people for other things. We felt like we hit that point.
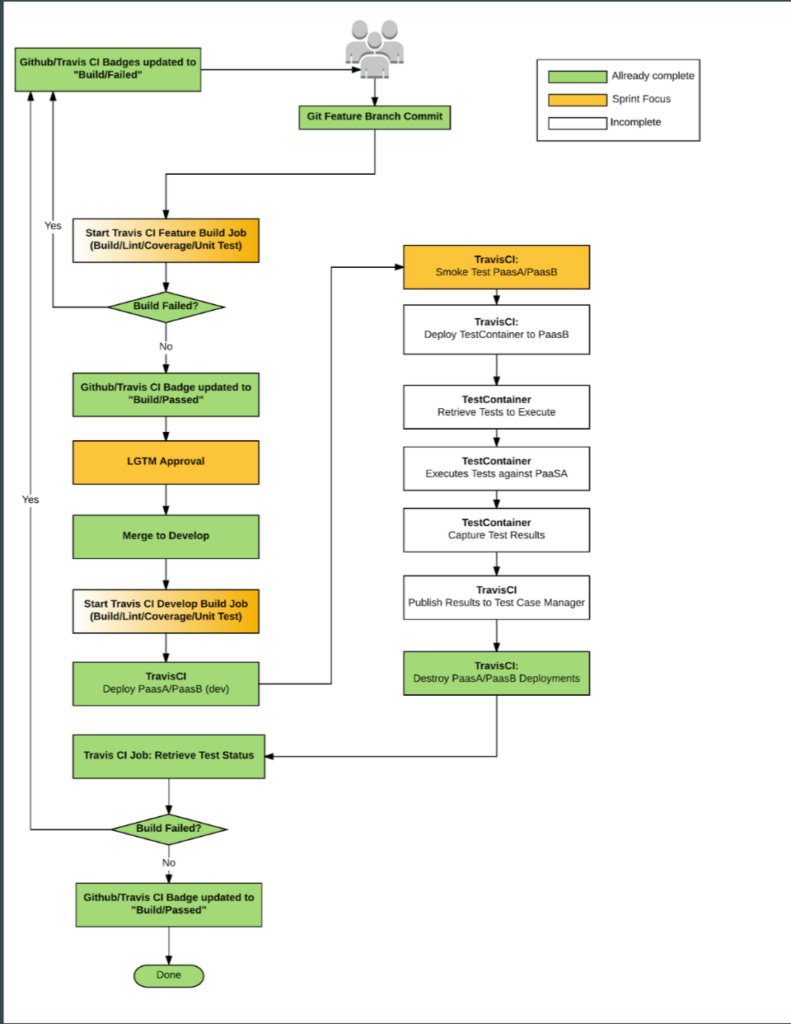
Here is what our current test workflow looks like. Its subject to change but this is our most recent iteration.
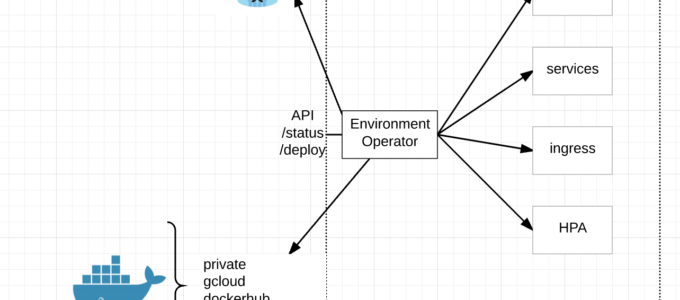
Notice we are running TravisCI to kick everything off. If you have read our other blog posts, you know we also have a Jenkins plugin and you are probably thinking, ‘why Travis when you already have written your own Jenkins plugin?’ Its rather simple really. We use TravisCI to kick off tests through Github which deploys a completely new AWS VPC / Kubernetes Cluster from scratch, runs a series of tests to make sure it came up properly, all the endpoints are available and the deploys Jenkins into a namespace which kicks off a series of internal tests on the cluster.
Basically TravisCI is for external / infrastructure testing to make sure Terraform/Ansible run correctly and all the external dependencies come up and Jenkins to deploy / test at the container level for internal components.
If you haven’t already read it, you may consider reading Kubernetes A/B Cluster Deploys because we are capable of deploying two completely separate clusters inside the same AWS VPC for the purpose of A/B migrations.
Travis looks at any pull requests (PR) being made to our dev branch. For each PR TravisCI will run through the complete QA automation process. Below are the highlights. You can look at the image above for details.
1. create a branch from the PR and merge in the dev branch
2. Linting/Unit tests
3. Cluster deploy
- If anything fails during deploy of the VPC, paasA or paasB, the process will fail, and tear down the environment with the logs of it in TravisCI build logs.
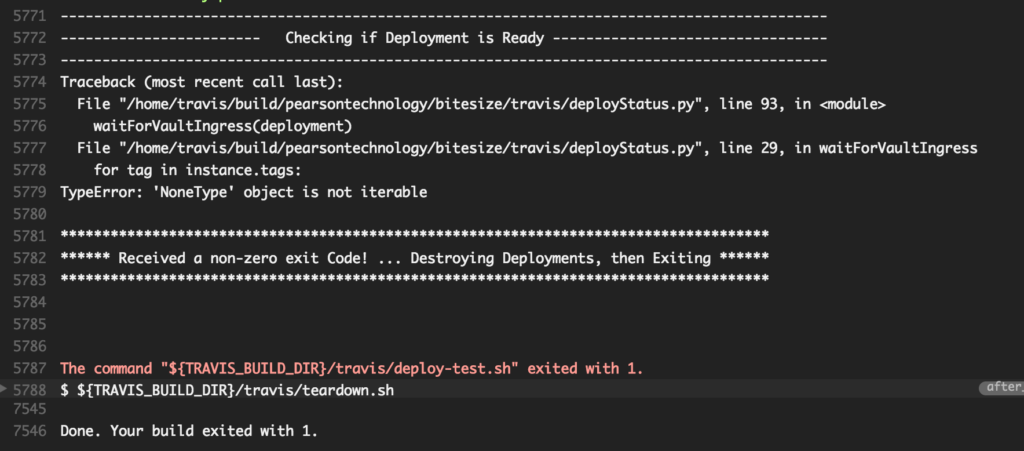
Here is an example of one of our builds that is failing from the TravisCI.
4. Test paasA with paasB
- Smoke Test
- Deploy ‘Testing’ containers into paasB
- Retrieve tests
- Execute tests against paasA
- Capture results
- Publish back to Travis
5. Destroy environment
One massive advantage of having A and B clusters is we can use one to test the other. This enables a large portion of our testing automation to exist in containers. Thus making our test automation parallel, fast and scalable to a large extent.
The entire process takes about 25 minutes. Not too shabby for literally building an entire environment from the ground up and running tests against it and we don’t expect the length of time to change much. In large part because of the parallel testing. This is a from scratch, completely automated QA automation framework for PaaS. I’m thinking 25-30 minutes is pretty damn good. You?
Alright get to the testing already.
First is our helper script for setting a few params like timeouts and numbers of servers for each type. anything in ‘${}’ is a Terraform variable that we inject on Terraform deploy.
helper.bash
#!/bin/bash
## Statics
#Long Timeout (For bootstrap waits)
LONG_TIMEOUT=<integer_seconds>
#Normal Timeout (For kubectl waits)
TIMEOUT=<integer_seconds>
# Should match minion_count in terraform.tfvars
MINION_COUNT=${MINION_COUNT}
LOADBALANCER_COUNT=${LOADBALANCER_COUNT}
ENVIRONMENT=${ENVIRONMENT}
## Functions
# retry_timeout takes 2 args: command [timeout (secs)]
retry_timeout () {
count=0
while [[ ! `eval $1` ]]; do
sleep 1
count=$((count+1))
if [[ "$count" -gt $2 ]]; then
return 1
fi
done
}
# values_equal takes 2 values, both must be non-null and equal
values_equal () {
if [[ "X$1" != "X" ]] || [[ "X$2" != "X" ]] && [[ $1 == $2 ]]; then
return 0
else
return 1
fi
}
# min_value_met takes 2 values, both must be non-null and 2 must be equal or greater than 1
min_value_met () {
if [[ "X$1" != "X" ]] || [[ "X$2" != "X" ]] && [[ $2 -ge $1 ]]; then
return 0
else
return 1
fi
}
You will notice we have divided our high level tests by Kubernetes resource types. Services, Ingresses, Pods etc etc
First we test a few things to make sure our minions and loadbalancer (minions) came up. Notice we are using kubectl for much of this. May as well, its there and its easy.
If you want to know more about what we mean by load balancer minions.
instance_counts.bats
#!/usr/bin/env bats
set -o pipefail
load ../helpers
# Infrastructure
@test "minion count" {
MINIONS=`kubectl get nodes --selector=role=minion --no-headers | wc -l`
min_value_met $MINION_COUNT $MINIONS
}
@test "loadbalancer count" {
LOADBALANCERS=`kubectl get nodes --selector=role=loadbalancer --no-headers | wc -l`
values_equal $LOADBALANCERS $LOADBALANCERS
}
pod_counts.bats
#!/usr/bin/env bats
set -o pipefail
load ../helpers
@test "bitesize-registry pods" {
BITESIZE_REGISTRY_DESIRED=`kubectl get rc bitesize-registry --namespace=default -o jsonpath='{.spec.replicas}'`
BITESIZE_REGISTRY_CURRENT=`kubectl get rc bitesize-registry --namespace=default -o jsonpath='{.status.replicas}'`
values_equal $BITESIZE_REGISTRY_DESIRED $BITESIZE_REGISTRY_CURRENT
}
@test "kube-dns pods" {
KUBE_DNS_DESIRED=`kubectl get rc kube-dns-v18 --namespace=kube-system -o jsonpath='{.spec.replicas}'`
KUBE_DNS_CURRENT=`kubectl get rc kube-dns-v18 --namespace=kube-system -o jsonpath='{.status.replicas}'`
values_equal $KUBE_DNS_DESIRED $KUBE_DNS_CURRENT
}
@test "consul pods" {
CONSUL_DESIRED=`kubectl get rc consul --namespace=kube-system -o jsonpath='{.spec.replicas}'`
CONSUL_CURRENT=`kubectl get rc consul --namespace=kube-system -o jsonpath='{.status.replicas}'`
values_equal $CONSUL_DESIRED $CONSUL_CURRENT
}
@test "vault pods" {
VAULT_DESIRED=`kubectl get rc vault --namespace=kube-system -o jsonpath='{.spec.replicas}'`
VAULT_CURRENT=`kubectl get rc vault --namespace=kube-system -o jsonpath='{.status.replicas}'`
values_equal $VAULT_DESIRED $VAULT_CURRENT
}
@test "es-master pods" {
ES_MASTER_DESIRED=`kubectl get rc es-master --namespace=default -o jsonpath='{.spec.replicas}'`
ES_MASTER_CURRENT=`kubectl get rc es-master --namespace=default -o jsonpath='{.status.replicas}'`
values_equal $ES_MASTER_DESIRED $ES_MASTER_CURRENT
}
@test "es-data pods" {
ES_DATA_DESIRED=`kubectl get rc es-data --namespace=default -o jsonpath='{.spec.replicas}'`
ES_DATA_CURRENT=`kubectl get rc es-data --namespace=default -o jsonpath='{.status.replicas}'`
values_equal $ES_DATA_DESIRED $ES_DATA_CURRENT
}
@test "es-client pods" {
ES_CLIENT_DESIRED=`kubectl get rc es-client --namespace=default -o jsonpath='{.spec.replicas}'`
ES_CLIENT_CURRENT=`kubectl get rc es-client --namespace=default -o jsonpath='{.status.replicas}'`
values_equal $ES_CLIENT_DESIRED $ES_CLIENT_CURRENT
}
@test "monitoring-heapster-v6 pods" {
HEAPSTER_DESIRED=`kubectl get rc monitoring-heapster-v6 --namespace=kube-system -o jsonpath='{.spec.replicas}'`
HEAPSTER_CURRENT=`kubectl get rc monitoring-heapster-v6 --namespace=kube-system -o jsonpath='{.status.replicas}'`
values_equal $HEAPSTER_DESIRED $HEAPSTER_CURRENT
}
service.bats
#!/usr/bin/env bats
set -o pipefail
load ../helpers
# Services
@test "kubernetes service" {
retry_timeout "kubectl get svc kubernetes --namespace=default --no-headers" $TIMEOUT
}
@test "bitesize-registry service" {
retry_timeout "kubectl get svc bitesize-registry --namespace=default --no-headers" $TIMEOUT
}
@test "fabric8 service" {
retry_timeout "kubectl get svc fabric8 --namespace=default --no-headers" $TIMEOUT
}
@test "kube-dns service" {
retry_timeout "kubectl get svc kube-dns --namespace=kube-system --no-headers" $TIMEOUT
}
@test "kube-ui service" {
retry_timeout "kubectl get svc kube-ui --namespace=kube-system --no-headers" $TIMEOUT
}
@test "consul service" {
retry_timeout "kubectl get svc consul --namespace=kube-system --no-headers" $TIMEOUT
}
@test "vault service" {
retry_timeout "kubectl get svc vault --namespace=kube-system --no-headers" $TIMEOUT
}
@test "elasticsearch service" {
retry_timeout "kubectl get svc elasticsearch --namespace=default --no-headers" $TIMEOUT
}
@test "elasticsearch-discovery service" {
retry_timeout "kubectl get svc elasticsearch-discovery --namespace=default --no-headers" $TIMEOUT
}
@test "monitoring-heapster service" {
retry_timeout "kubectl get svc monitoring-heapster --namespace=kube-system --no-headers" $TIMEOUT
}
ingress.bats
#!/usr/bin/env bats
set -o pipefail
load ../helpers
# Ingress
@test "consul ingress" {
retry_timeout "kubectl get ing consul --namespace=kube-system --no-headers" $TIMEOUT
}
@test "vault ingress" {
retry_timeout "kubectl get ing vault --namespace=kube-system --no-headers" $TIMEOUT
}
Now that we have a pretty good level of certainty the cluster stood up as expected, we can begin deeper testing into the various components and integrations within our platform. Stackstorm, Kafka, ElasticSearch, Grafana, Keycloak, Vault and Consul. AWS endpoints, internal endpoints, port mappings, security……….. and the list goes on. All core components that our team provides our customers.
Stay tuned for more as it all begins to fall into place.