Everything thing mentioned has been POCed and proven to work so far in testing. We run an application called Pulse in which we demoed it staying up throughout this A/B migration process.
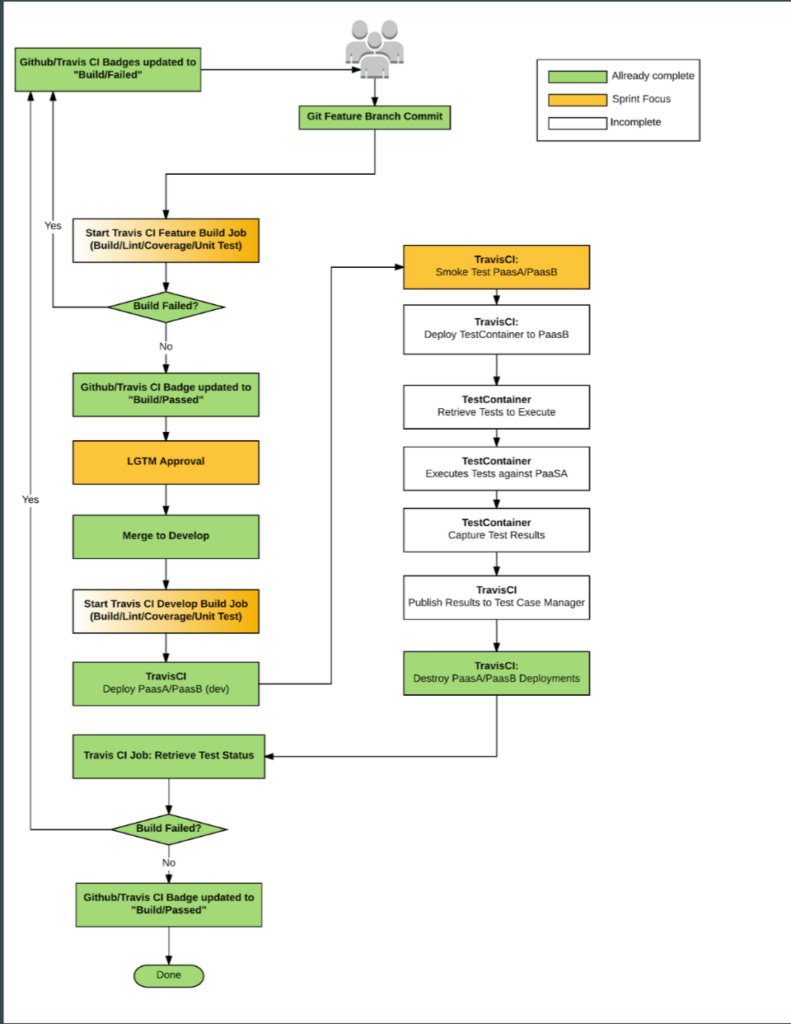
Recently the team went through an exercise on how to deploy/manage a complete cluster upgrade. There were a couple options discussed along with what it would take to accomplish both.
- In-situ upgrade – the usual
- A/B upgrade – a challenge
In the end, we chose to move forward with A/B upgrades. Keeping in mind the vast majority of our containers are stateless and thus quite easy to move around. Stateful containers are a bit bigger beast but we are working on that as well.
We fully understand A/B migrations will be difficult and In-situ will be required at some point but what the hell. Why not stretch ourselves a bit right?
So here is the gist:
Build a Terraform/Ansible code base that can deploy an AWS VPC with all the core components. Minus the databases in this picture this is basically our shell. Security groups, two different ELBs for live and pre-live, a bastion box, subnets and routes, our dns hosted zone and a gateway.
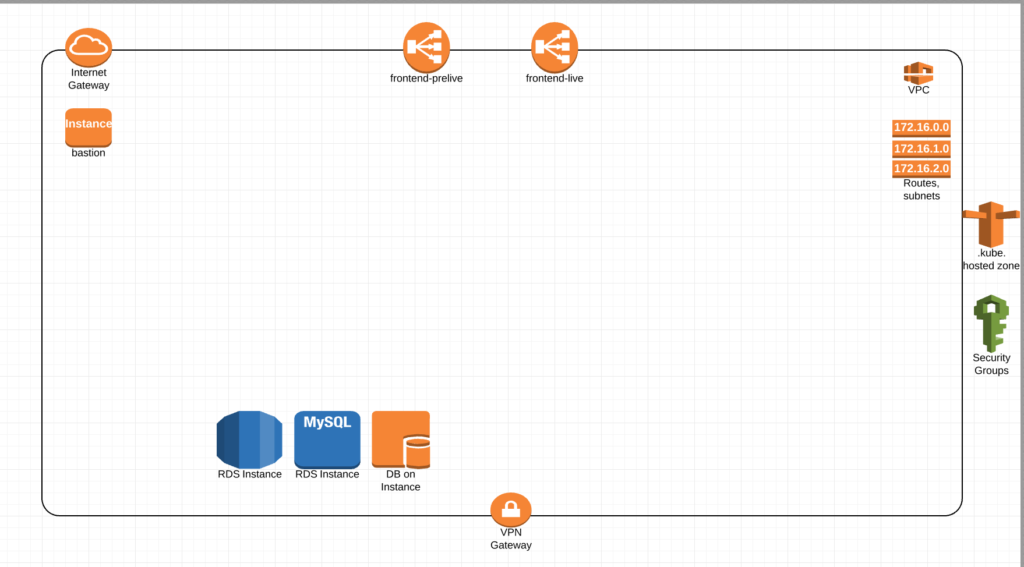
This would be its own Terraform apply. Allowing our Operations folks to manage security groups, some global dns entries, any VPN connections, bastion access etc etc without touching the actual Kubernetes clusters.
We would then have a separate Terraform apply that will stand up what we call paasA. Which includes an Auth server, our Kubernetes nodes for load balancing (running ingress controllers), master-a, and all of our minions with the kubernetes ingress-controllers receiving traffic through frontend-live ELB.
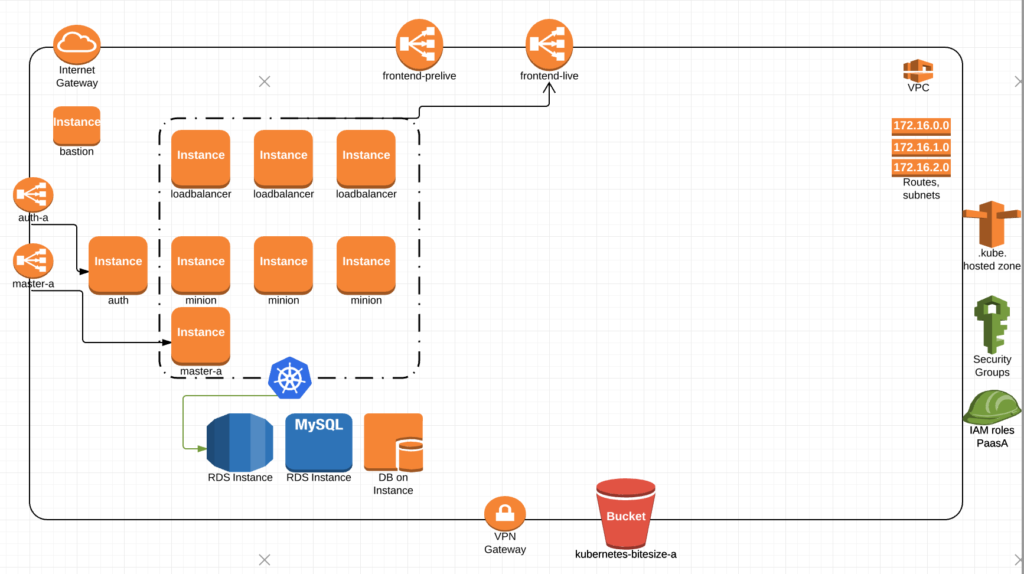
Once we decide to upgrade, we would spin up paasB. which is essentially a duplicate of paasA running within the same VPC.
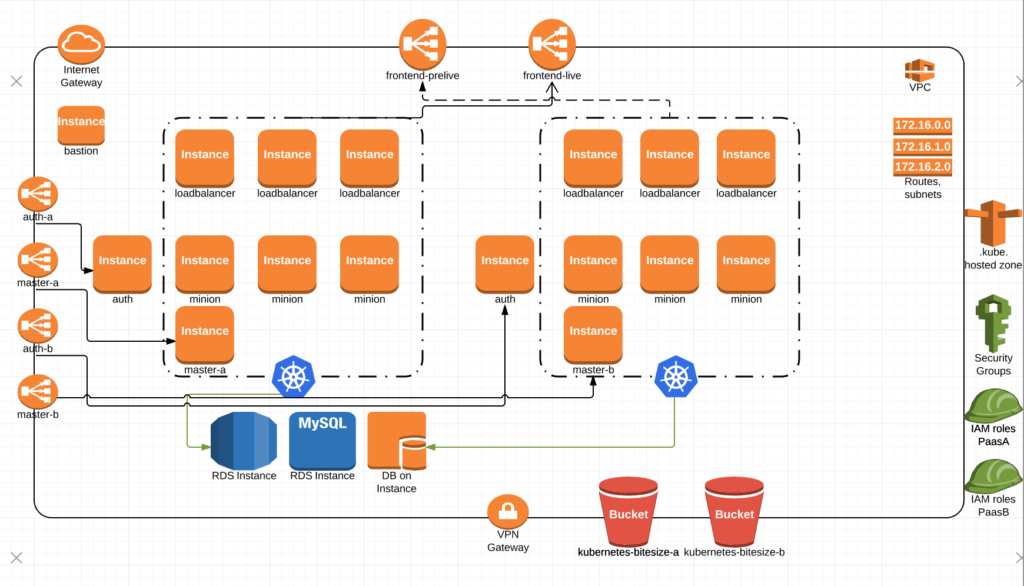
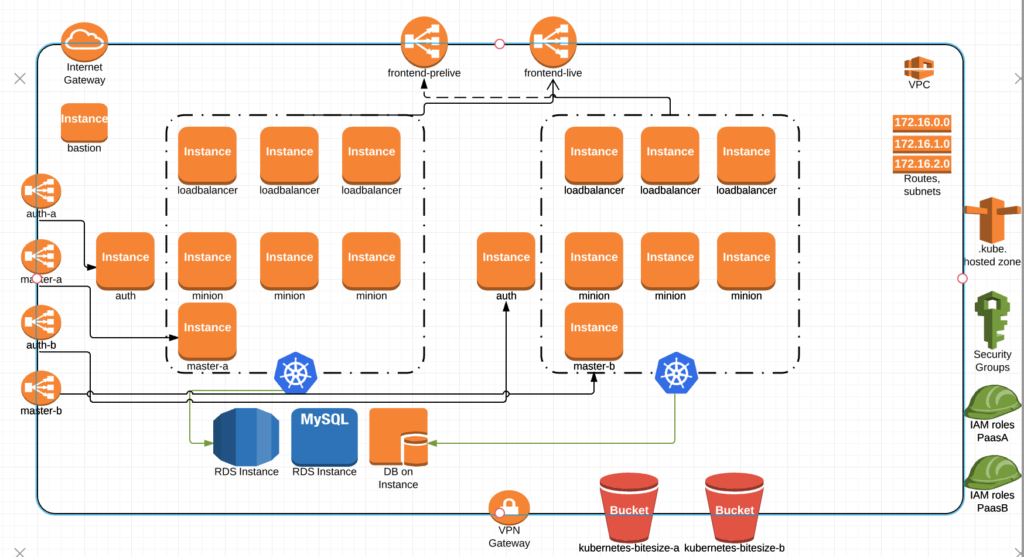
When paasB comes up, it gets added to the frontend pre-live ELB for smoke testing, end-to-end testing and the like.
Once paasB is tested to our satisfaction, we make the switch to the live ELB while preserving the ability to switch back if we find something major preventing a complete cut-over.
We then bring down paasA and wwwaaaahhhllllllaaaaaa, PaaS upgrade complete.
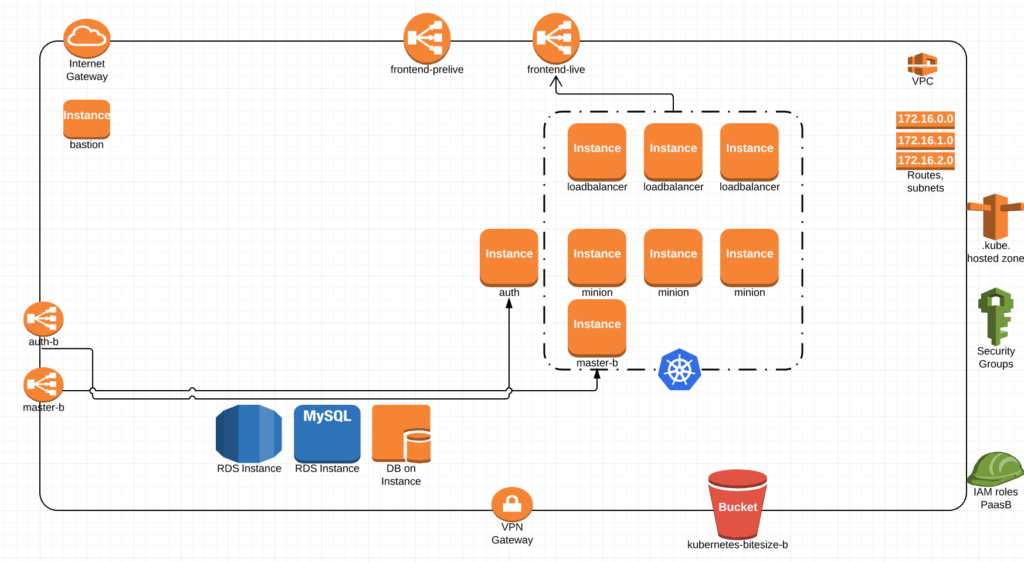
Now I think its obvious I’m way over simplifying this so lets get into some details.
ELBs – They stay up all the time. Our Kubernetes minions running nginx-controllers get labelled in AWS. So we can quickly update the ELBs whether live or prelive to point at the correct servers.
S3 buckets – We store our config files and various execution scripts in S3 for configuring our minions and the master. In this A/B scenario, each Cluster (paasA and paas) have their own S3 bucket where their config files are stored.
Auth Servers – Our paas deploys include our Keycloak Auth servers. We still need to work through how we transfer all the configurations or IF we choose to no longer deploy auth servers as apart of the Cluster deploy but instead as apart of the VPC.
Masters – New as apart of cluster deploy in keeping with true A/B.
Its pretty cool to run two clusters side by side AND be able to bring them up and down individually. But where this gets really awesome is when we can basically take all applications running in paasA and deploy them into paasB. I’m talking about a complete migration of assets. Secrets, Jenkins, Namespaces, ACLs, Resource Quotas and ALL applications running on paasA minus any self generated items.
To be clear, we are not simply copying everything over. We are recreating objects using one cluster as the source and the other cluster as the destination. We are reading JSON objects from the Kubernetes API and using those objects along with their respective configuration to create the same object in another cluster. If you read up on Ubernetes, you will find their objectives are very much in-line with this concept. We also have ZERO intent of duplicating efforts long term. The reality is, we needed this functionality before the Kubernetes project could get there. As Kubernetes federation continues to mature, we will continue to adopt and change. Even replacing our code with theirs. With this in mind, we have specifically written our code to perform some of these actions in a way that can very easily be removed.
Now you are thinking, why didn’t you just contribute back to the core project? We are in several ways. Just not this one because we love the approach the Kubernetes team is already taking with this. We just needed something to get us by until they can make theirs production ready.
Now with that I will say we have some very large advantages that enable us to accomplish something like this. Lets take Jenkins for example. We run Jenkins in every namespace in our clusters. Our Jenkins machines are self-configuring and for the most part stateless. So while we have to copy infrastructure level items like Kubernetes Secrets to paasB, we don’t have to copy each application. All we have to do is spin up the Jenkins container in each namespace and let them deploy all the applications necessary for their namespace. All the code and configuration to do so exists in Git repos. Thus PaaS admins don’t need to know how each application stack in our PaaS is configured. A really really nice advantage.
Our other advantage is, our databases currently reside outside of Kubernetes (except some mongo and cassandra containers in dev) on virtual machines. So we aren’t yet worried about migration of stateful data sets thus it has made our work around A/B cluster migrations a much smaller stepping stone. We are however placing significant effort into this area. We are getting help from the guys at Jetstack.io around storage and we are working diligently with people like @chrislovecnm to understand how we can bring database containers into production. Some of this is reliant upon new features like Petsets and some of it requires changes in how various databases work. Take for example Cassandra snitches where Chris has managed to create a Kubernetes native snitch. Awesome work Chris.
So what about Consul, its stateful right? And its in your cluster yes?
Well that’s a little different animal. Consul is a stateful application in that it runs in a cluster. So we are considering two different ways by which to accomplish this.
- Externalize our flannel overlay network using aws-vpc and allow the /16s to route to one another. Then we could essentially create one Consul cluster across two Kubernetes clusters, allow data to sync and then decommission the consul containers on the paasA.
- Use some type of small application to keep two consul clusters in sync for a period of time during paas upgrade.
Both of the options above have benefits and limitations.
Option 1:
- Benefits:
- could use a similar method for other clustered applications like Cassandra.
- would do a better job ensuring the data is synced.
- could push data replication to the cluster level where it should be.
- Limitations:
- we could essentially bring down the whole Consul cluster with a wrong move. Thus some of the integrity imagined in a full A/B cluster migration would be negated.
Option 2:
- Benefits:
- keep a degree of separation between each Kubernetes cluster during upgrade so one can not impact the other.
- pretty easy to implement
- Limitations:
- specific implementation
- much more to keep track of
- won’t scale for other stateful applications
I’m positive the gents on my team will call me out on several more but this is what I could think off off the top.
We have already implemented Option #2 in a POC of our A/B migration.
But we haven’t chosen a firm direction with this yet. So if you have additional insight, please comment back.
Barring stateful applications, what are we using to migrate all this stuff between clusters? StackStorm. We already have it performing other automation tasks outside the cluster, we have python libraries k8sv1 and k8sv1beta for the Kubernetes API endpoints and its quite easy to extract the data and push it into another cluster. Once we are done with the POC we’ll be pushing this to our stackstorm repo here. @peteridah you rock.
In our current POC, we migrate everything. In our next POC, we’ll enable the ability to deploy specific application stacks from one cluster to another. This will also provide us the ability to deploy an application stack from one cluster into another for things like performance testing or deep breach management testing.
Lastly we are working through how to go about stateful container migrations. There are many ideas floating around but we would really enjoy hearing yours.
For future generations:
- We will need some sort of metadata framework for those application stacks that span multiple namespaces to ensure we duplicate an environment properly.
To my team-
My hat off to you. Martin, Simas, Eric, Yiwei, Peter, John, Ben and Andy for all your work on this.