We recently upgraded Kube-dns.
gcr.io/google_containers/kubedns-amd64:1.6 gcr.io/google_containers/kube-dnsmasq-amd64:1.3
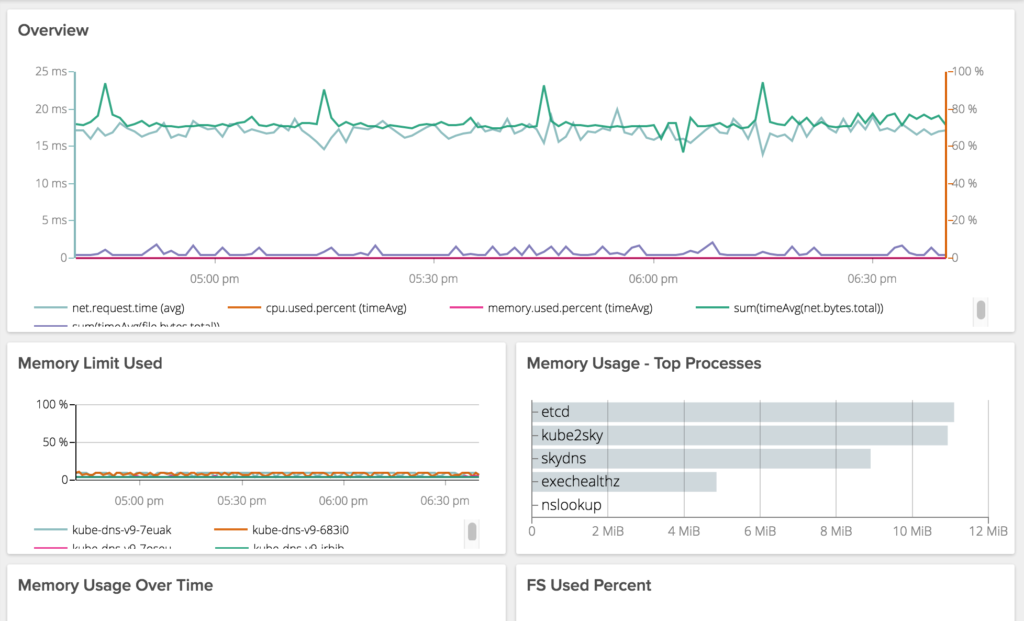
Having used SkyDNS up to this point, we ran into some unexpected performance issues. In particular we were seeing pretty exaggerated response times from kube-dns when making requests it is not authoritative on (i.e. not cluster.local).
Fortunately this was on a cluster not yet serving any production customers.
It took several hours of troubleshooting and getting a lot more familiar with our new DNS and Dnsmasq, in particular the various knobs we could turn but what hinted us off to our solution was the following issue.
https://github.com/kubernetes/kubernetes/issues/27679
** Update
Adding the following line to our “- args” config under gcr.io/google_containers/kubednsmasq-amd64:1.3 did the trick and significantly improved dns performance.
- --server=/cluster.local/127.0.0.1#10053 - --resolv-file=/etc/resolv.conf.pods
By adding the second entry we ensure requests only go upstream from kube-dns instead of back to the host level resolver.
/etc/resolv.conf.pods points only to external dns, in our case, AWS DNS for our VPC which is always %.%.%.2 for whatever your VPC IP range is.
** End Update
In either case, we have significantly improved performance on DNS lookups and are excited to see how our new DNS performs under load.
Final thoughts:
Whether tuning for performance or not realizing your cluster requires a bit more than 200Mi RAM and 1/10 of a CPU, its quite easy to overlook kube-dns as a potential performance bottleneck.
We have a saying on the team, if its slow, check dns. If it looks good, check it again. And if it still looks good, have someone else check it. Then move on to other things.
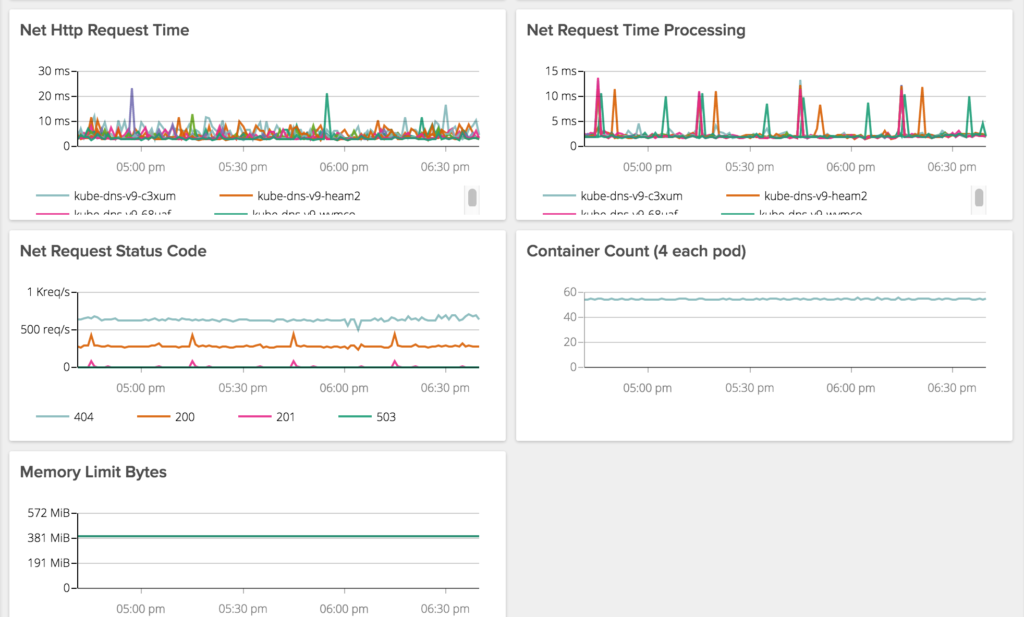
Kube-dns has bit us so many times, we have a dashboard to monitor and alert just on it. These are old screen caps from SkyDNS but you get the point.